How Kafka Works with Same and Different Consumer Groups
Introduction to Apache Kafka
Apache Kafka is an open-source distributed event streaming platform for building real-time data pipelines and streaming applications. Kafka allows you to publish, subscribe, store, and process streams of records in a fault-tolerant manner. Kafka achieves this by using topics, partitions, and consumer groups to manage data flow efficiently.
Kafka Key Components:
- Topics: A topic is a category or feed name to which records are published. Topics are split into partitions for scalability.
- Partitions: A partition is a subset of a topic, allowing Kafka to parallelize message processing.
- Producers: Producers are clients that publish (write) messages to a Kafka topic.
- Consumers: Consumers are clients who subscribe to (read) messages from a Kafka topic.
- Brokers: Brokers are servers that store and serve messages.
What are Kafka Consumer Groups?
A consumer group in Kafka is a collection of one or more consumers that work together to consume messages from a set of topics. Consumer groups enable parallel processing of messages and ensure that each message is processed only once by a single consumer within a group.
Key Properties of Consumer Groups:
- Group ID: Each consumer group is identified by a unique group ID.
- Partition Assignment: Kafka assigns partitions to consumers within the same group. Only one consumer consumes a partition within the group.
- Message Processing: Kafka guarantees that each message is consumed exactly once by any of the consumers in the group.
Kafka with Consumers in the Same Consumer Group

When multiple consumers are part of the same consumer group, Kafka distributes messages from topic partitions across all consumers in that group. This means that each message is processed by only one consumer in the group. Let’s understand this with an example.
Scenario: Consumers in the Same Group
Imagine a topic my_topic with three partitions (Partition 0, Partition 1, Partition 2), and three consumers (Consumer 1, Consumer 2, and Consumer 3) all part of the same consumer group (consumer_group_1).
Partition Assignment:
Consumer 1is assignedPartition 0.Consumer 2is assignedPartition 1.Consumer 3is assignedPartition 2.
Since all consumers belong to the same group, each consumer will receive messages from only its assigned partition. There is no duplication of messages within the group.
Message Flow Diagram: Same Consumer Group
+-------------+ +-------------+
| Broker 1 |<------------>| Consumer 1 |
| (Partition0)| | (Group: A) |
| (Leader) | +-------------+
+-------------+
+-------------+ +-------------+
| Broker 2 |<------------>| Consumer 2 |
| (Partition1)| | (Group: A) |
| (Leader) | +-------------+
+-------------+
+-------------+ +-------------+
| Broker 3 |<------------>| Consumer 3 |
| (Partition2)| | (Group: A) |
| (Leader) | +-------------+
+-------------+- Advantage: Parallel processing and scalability.
- Use Case: This setup is ideal when you want to process large volumes of data quickly, and each message needs to be processed only once.
Kafka with Consumers in Different Consumer Groups
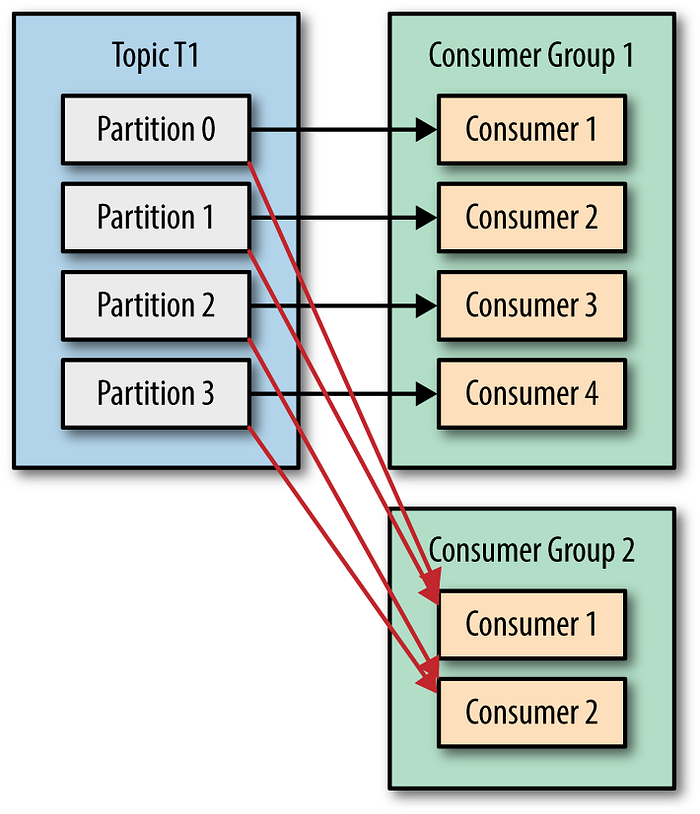
When consumers are part of different consumer groups, each group independently consumes the messages from the topic. This means that every consumer group receives a full copy of the data stream.
Scenario: Consumers in Different Groups
Consider the same topic my_topic with three partitions (Partition 0, Partition 1, Partition 2), but now each consumer belongs to a different consumer group:
- Consumer Group Assignment:
Consumer 1is inconsumer_group_1.Consumer 2is inconsumer_group_2.Consumer 3is inconsumer_group_3.
Each consumer group independently reads from the topic, so all consumers receive all messages from all partitions.
Message Flow Diagram: Different Consumer Groups
+------------------+
| Broker |
| (Partitions) |
+--------+---------+
|
+---------------+----------------+
| | |
+-------+-----+ +------+--------+ +-----+-------+
| Consumer 1 | | Consumer 2 | | Consumer 3 |
| (Group: A) | | (Group: B) | | (Group: C) |
+-------------+ +---------------+ +-------------+- Advantage: Each consumer group receives all messages, allowing multiple independent applications to process the same data.
- Use Case: Ideal for scenarios where different applications or services need to consume and process the same data stream independently, such as logging, monitoring, and auditing.
Practical Examples with Python
Now, let’s look at some practical Python examples using the kafka-python library to demonstrate these concepts.
Producer Code
This producer will send messages to a topic called my_topic:
from kafka import KafkaProducer
import time
# Kafka producer with multiple broker URLs
producer = KafkaProducer(
bootstrap_servers=['url1','url2']
)
def send_messages():
for i in range(10):
message = f"Message {i}".encode('utf-8')
producer.send('my_topic', value=message)
print(f"Sent: {message}")
time.sleep(1)
producer.flush()
producer.close()
if __name__ == "__main__":
send_messages()Consumer Code: Same Consumer Group
Three consumers in the same group (consumer_group_1):
from kafka import KafkaConsumer
import threading
def start_consumer(consumer_id):
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers=['url1','url2'],
group_id='consumer_group_1',
auto_offset_reset='earliest'
)
print(f"Consumer {consumer_id} started...")
for message in consumer:
print(f"Consumer {consumer_id} received: {message.value.decode('utf-8')}")
if __name__ == "__main__":
for i in range(1, 4):
threading.Thread(target=start_consumer, args=(i,)).start()Consumer Code: Different Consumer Groups
Three consumers in different groups:
from kafka import KafkaConsumer
import threading
def start_consumer(consumer_id, group_id):
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers=['url1','url2'],
group_id=group_id,
auto_offset_reset='earliest'
)
print(f"Consumer {consumer_id} started with group {group_id}...")
for message in consumer:
print(f"Consumer {consumer_id} received: {message.value.decode('utf-8')}")
if __name__ == "__main__":
group_ids = ['consumer_group_1', 'consumer_group_2', 'consumer_group_3']
for i, groupConclusion

Apache Kafka provides flexibility in message consumption through its consumer group mechanism. By understanding how Kafka handles consumers in the same and different consumer groups, you can optimize your data processing pipelines for different use cases, such as parallel processing or independent consumption by multiple applications.
Using the practical examples and visualizations provided, you can now implement and manage your Kafka consumer groups effectively, whether for scaling your applications or for ensuring reliable, independent data processing.